Steel Plate Fault Classifier
Data-driven fault detection in steel plates using Random Forest and Gradient Boosting, with feature selection insights.
OVERVIEW
This project aimed to develop a predictive machine learning model to classify faults in steel plates based on numerical features collected during manufacturing. By identifying patterns associated with common defects, the model supports proactive quality control and defect reduction.
KEY FEATURES & IMPLEMENTATION
• Data preprocessing including scaling, cleaning, and feature selection via Chi-square analysis
• Multi-class classification using Random Forest and Gradient Boosting models
• Performance evaluation through sample dataset predictions
• Visualization of fault distribution and feature importance
TECHNOLOGIES USED
Python, Scikit-learn, Pandas, NumPy, Matplotlib, Seaborn, Jupyter Notebook
CHALLENGES
• Addressing class imbalance and overfitting on rare fault types
• Extracting the most informative features from a noisy industrial dataset
• Ensuring consistency in classification outcomes across samples
LEARNINGS & IMPACT
This project enhanced my understanding of ensemble classification and industrial fault detection. It also demonstrated how statistical feature selection and model tuning can significantly improve classification reliability in real-world applications.
SCREENSHOTS & DIAGRAMS
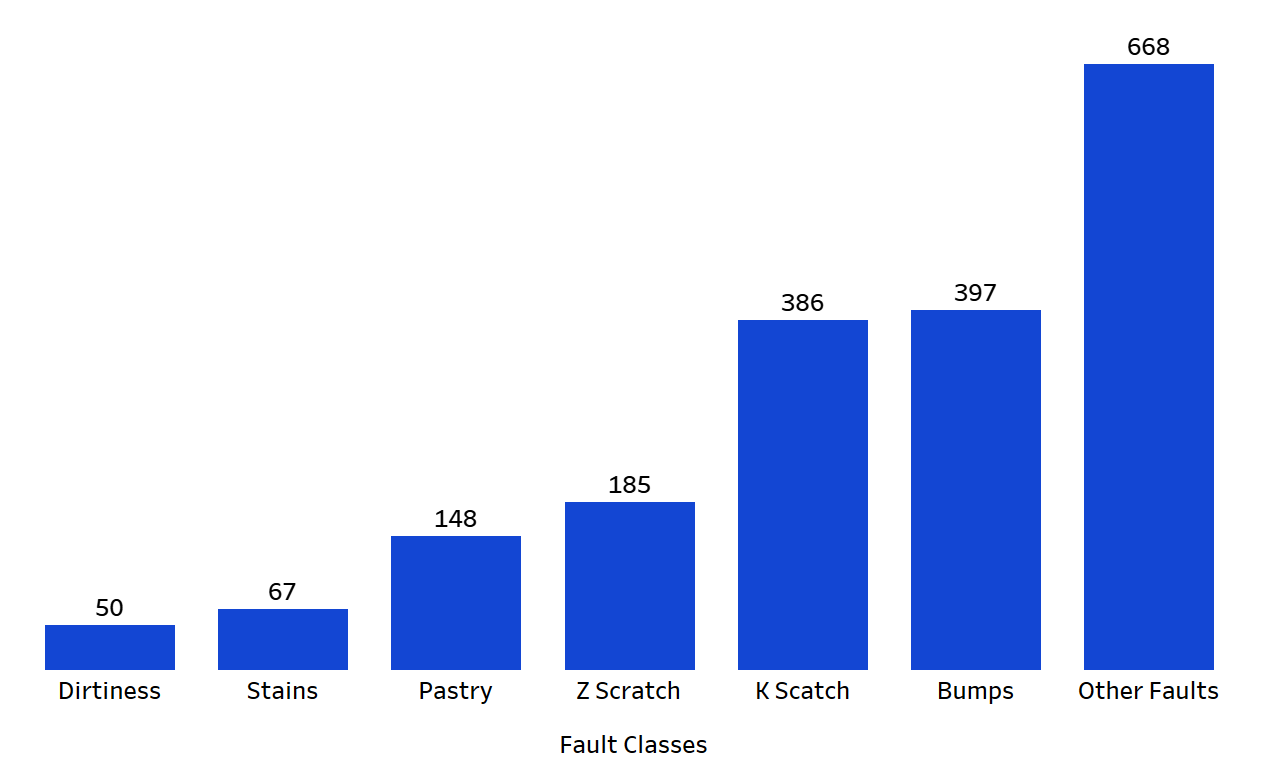
Figure 1. Original dataset class distribution showing imbalance across fault types
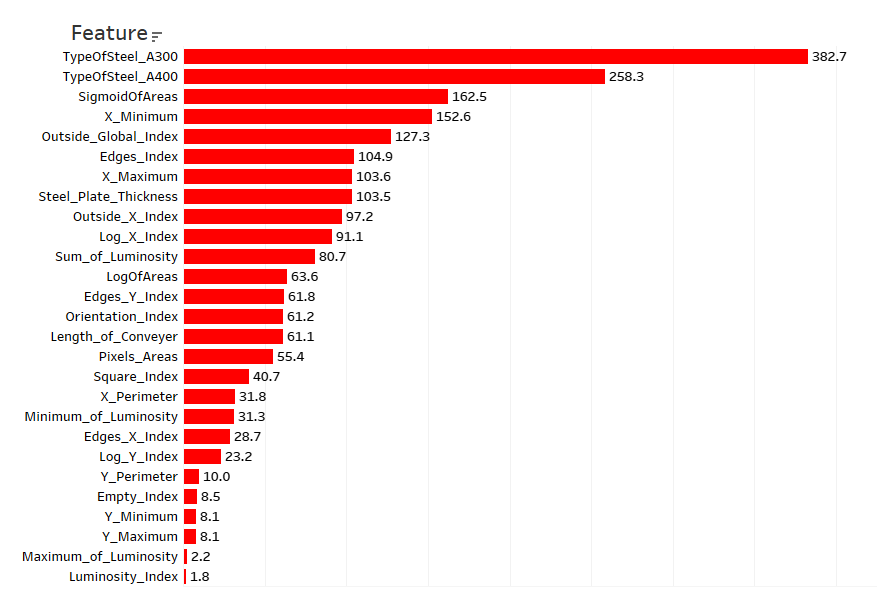
Figure 2. Chi-square feature importance — identifying the most predictive attributes

Figure 3. Distribution of predicted fault classes in sample data using Gradient Boosting
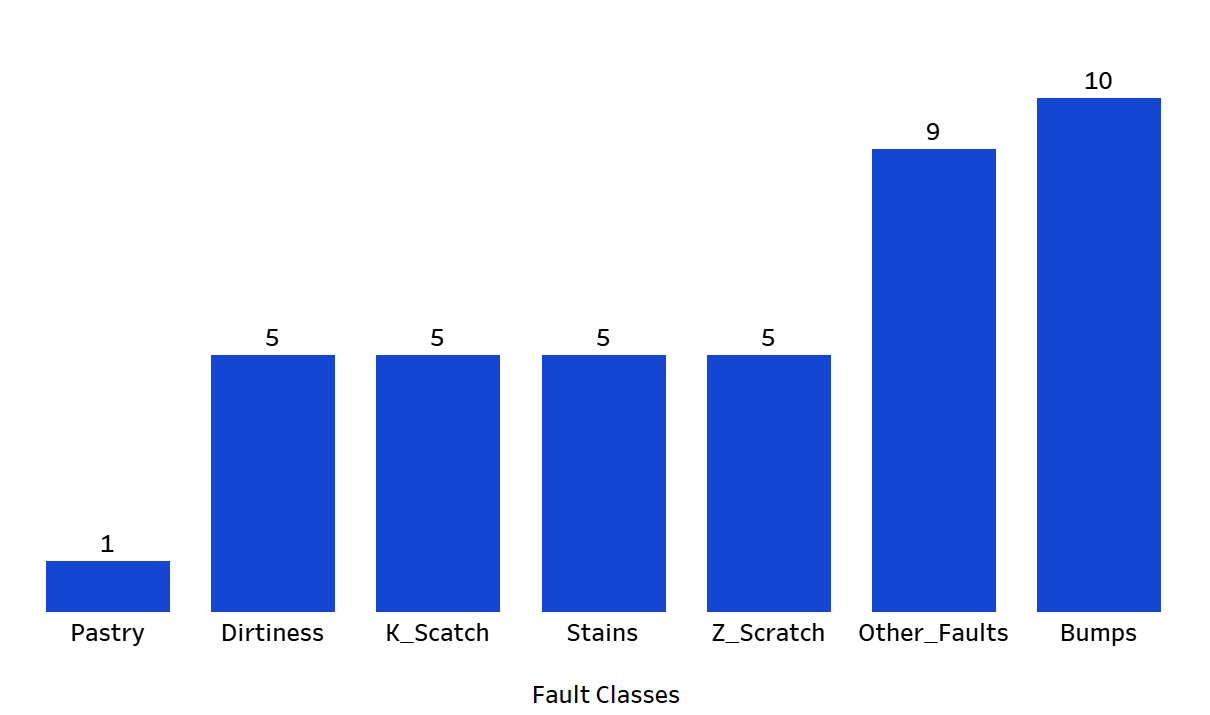
Figure 4. Distribution of predicted fault classes in sample data using Random Forest